Olá DBA, tudo bem por aí? Hoje atuei em um problema de lentidão causado por uma carga de dados em um ambiente DW, onde é necessário diariamente fazer ETL de tabelas muito grandes. A solução técnica sugerida ao desenvolvedor foi o uso de BULK COLLECT e FORALL para aumentar o desempenho da carga que era feita via PL/SQL. Neste post, vou exemplificar com dados fictícios o que foi feito.
Preparar o ambiente de testes com BULK COLLECT e FORALL
CREATE TABLE source AS
SELECT
LEVEL AS id,
'Owner_' || LEVEL AS owner,
'Object_' || LEVEL AS object_name,
'Type_' || MOD(LEVEL, 5) AS object_type,
SYSDATE - MOD(LEVEL, 365) AS created
FROM dual
CONNECT BY LEVEL <= 1000000;
CREATE TABLE target AS
SELECT * FROM source WHERE 1=0;
CREATE SEQUENCE seq_GUINA_TST
START WITH 1
INCREMENT BY 1
CACHE 1000;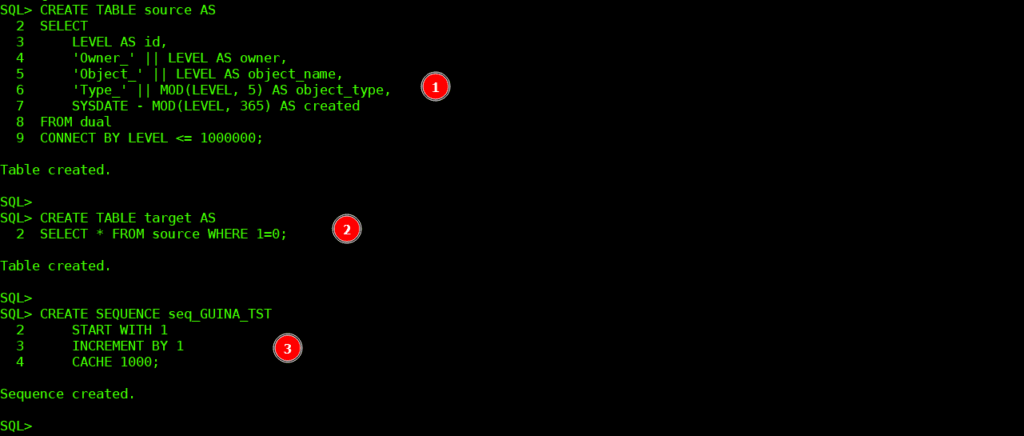
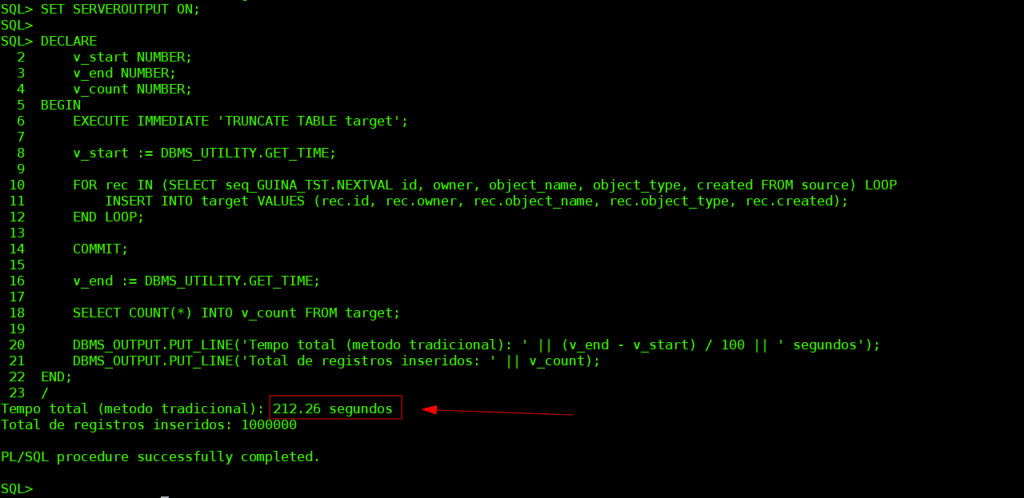
Método tradicional PL/SQL
SET SERVEROUTPUT ON;
SET TIMING ON;
set echo on;
DECLARE
v_start NUMBER;
v_end NUMBER;
v_count NUMBER;
BEGIN
EXECUTE IMMEDIATE 'TRUNCATE TABLE target';
v_start := DBMS_UTILITY.GET_TIME;
FOR rec IN (SELECT seq_GUINA_TST.NEXTVAL id, owner, object_name, object_type, created FROM source) LOOP
INSERT INTO target VALUES (rec.id, rec.owner, rec.object_name, rec.object_type, rec.created);
END LOOP;
COMMIT;
v_end := DBMS_UTILITY.GET_TIME;
SELECT COUNT(*) INTO v_count FROM target;
DBMS_OUTPUT.PUT_LINE('Tempo total (metodo tradicional): ' || (v_end - v_start) / 100 || ' segundos');
DBMS_OUTPUT.PUT_LINE('Total de registros inseridos: ' || v_count);
END;
/
set echo off;
SET TIMING off;O método tradicional sofre com troca de contexto entre o PL/SQL e o SQL. Para cada registro, o código alterna entre as duas camadas, gerando overhead e perda de performance.
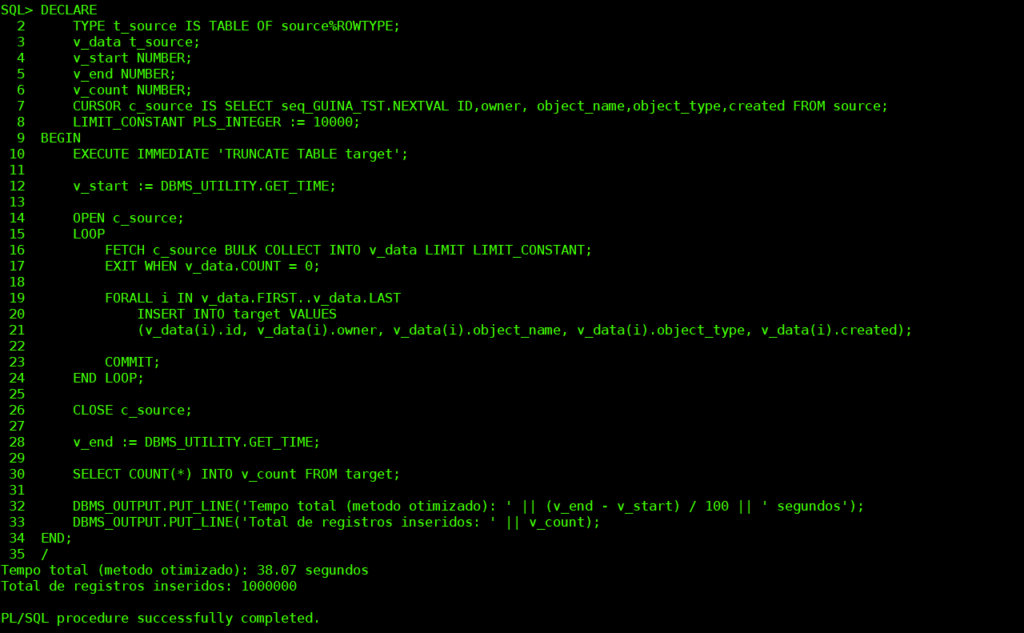
Método otimizado com BULK COLLECT e FORALL
SET SERVEROUTPUT ON;
SET TIMING ON;
set echo on;
DECLARE
TYPE t_source IS TABLE OF source%ROWTYPE;
v_data t_source;
v_start NUMBER;
v_end NUMBER;
v_count NUMBER;
CURSOR c_source IS SELECT seq_GUINA_TST.NEXTVAL ID,owner, object_name,object_type,created FROM source;
LIMIT_CONSTANT PLS_INTEGER := 10000;
BEGIN
EXECUTE IMMEDIATE 'TRUNCATE TABLE target';
v_start := DBMS_UTILITY.GET_TIME;
OPEN c_source;
LOOP
FETCH c_source BULK COLLECT INTO v_data LIMIT LIMIT_CONSTANT;
EXIT WHEN v_data.COUNT = 0;
FORALL i IN v_data.FIRST..v_data.LAST
INSERT INTO target VALUES
(v_data(i).id, v_data(i).owner, v_data(i).object_name, v_data(i).object_type, v_data(i).created);
COMMIT;
END LOOP;
CLOSE c_source;
v_end := DBMS_UTILITY.GET_TIME;
SELECT COUNT(*) INTO v_count FROM target;
DBMS_OUTPUT.PUT_LINE('Tempo total (metodo otimizado): ' || (v_end - v_start) / 100 || ' segundos');
DBMS_OUTPUT.PUT_LINE('Total de registros inseridos: ' || v_count);
END;
/
set echo off;
SET TIMING off;O uso de BULK COLLECT e FORALL reduz as trocas de contexto, permitindo que múltiplos registros sejam processados em uma única interação entre PL/SQL e SQL. Isso resulta em ganhos exponenciais de desempenho.
Resultados PL/SQL Usando Sequence
| Método | Tempo Total (segundos) | Registros Inseridos | Melhora (%) |
|---|---|---|---|
| Tradicional | 212.26 | 1.000.000 | – |
| BULK COLLECT + FORALL | 38.07 | 1.000.000 | 82% |
Com o método BULK COLLECT + FORALL, foi possível reduzir o tempo de execução em 82%, eliminando o gargalo causado pela troca de contexto entre PL/SQL e SQL e tornando o processo significativamente mais eficiente.
Resultados PL/SQL Sem Sequence
| Método | Tempo Total (segundos) | Registros Inseridos | Melhora (%) |
|---|---|---|---|
| Tradicional | 90.77 | 1.000.000 | – |
| BULK COLLECT + FORALL | 6,50 | 1.000.000 | 93% |
Ao testar o mesmo código com e sem o uso da sequência (SEQ_GUINA_TST.NEXTVAL), observamos uma diferença significativa no desempenho geral. O uso da sequência adiciona um overhead ao processo, enquanto sua remoção resulta em tempos de execução muito menores em ambos os métodos, tradicional e otimizado com BULK COLLECT e FORALL.
Sem o uso da sequência, os processos eliminam esse overhead, tornando-se consideravelmente mais rápidos. Além disso, a melhora de desempenho entre o método tradicional e o otimizado é ainda mais expressiva, com um ganho de 93% ao utilizar o método otimizado. Isso reforça como BULK COLLECT e FORALL potencializam a eficiência ao evitar operações desnecessárias, como o uso de sequência.
Cargas de dados com SQL PURO são mais rápidas, pois não há troca de contexto entre PL/SQL e SQL. Porém, é importante verificar se o ambiente suporta grandes cargas em uma única transação sem problemas de desempenho e se a infraestrutura atual é capaz de processar essa operação de uma só vez. Além disso, se os dados precisarem de tratamentos especiais, como cálculos ou validações ou qualquer outra coisa, será necessário usar um cursor em PL/SQL, mesmo com o custo extra da troca de contexto.
Drop dos objetos criados para teste
DROP TABLE source PURGE;
DROP TABLE target PURGE;
DROP SEQUENCE seq_GUINA_TST;zas
🧥🥼#20241210 #DBASobrinho #GuinaNãoTinhaDó #BóBó #CaceteDeAgulha #OracleACE 🧥🥼