Durante atendimentos a equipes de DevOps e DBAs, é comum encontrar consultas usando UNION de forma inadequada, aplicando um DISTINCT implícito sem necessidade. Muitos não conhecem a diferença real entre UNION e UNION ALL, nem os impactos práticos dessa escolha.
“Ah, mas é quase nada…” é uma resposta comum quando se fala sobre isso. Em uma consulta pontual, com poucos registros, pode até parecer inofensivo. Mas essa lógica muda completamente quando se trabalha com tabelas de milhões de linhas, ou com consultas que são executadas milhares de vezes por minuto. Nesse cenário, o SORT UNIQUE implícito do UNION deixa de ser detalhe e passa a ser gargalo sério.
Este post foi escrito justamente para explicar essa diferença com clareza, mostrar os impactos reais e ajudar a escolher com consciência qual operador usar, com exemplos simples, práticos e com plano de execução.
1 – Diferença conceitual
Os operadores UNION e UNION ALL pertencem à categoria de operadores de conjunto. Ambos combinam os resultados de múltiplos SELECTs, desde que apresentem o mesmo número de colunas e tipos compatíveis.
UNION
- Elimina registros duplicados após combinar os resultados
- Aplica internamente um
SORT UNIQUEpara ordenar e remover duplicatas - A operação gera maior uso de CPU, espaço temporário (
TEMP) e I/O - Recomendado apenas quando a lógica da aplicação exige retorno sem repetição
UNION ALL
- Apenas concatena os conjuntos, mantendo registros duplicados
- Não realiza ordenação nem filtragem
- Mais eficiente em termos de tempo, CPU e uso de recursos
- Ideal quando duplicatas são aceitáveis ou tratadas posteriormente
Resumo Prático
Se for necessário remover duplicatas, use UNION.
Se não houver essa necessidade, UNION ALL sempre será mais performático.
2 – Criar dados de teste
SQL>
CREATE TABLE t_func (
id_func NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
nome_func VARCHAR2(50),
departamento VARCHAR2(50),
cidade VARCHAR2(50)
);
-- Departamento: Financeiro
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Marina', 'Financeiro', 'São Paulo');
-- Departamento: RH
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Ana', 'RH', 'São Paulo');
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Beatriz', 'RH', 'São Paulo');
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Carlos', 'RH', 'Rio de Janeiro');
-- Departamento: TI
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Carlos', 'TI', 'Rio de Janeiro');
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Ana', 'TI', 'São Paulo');
INSERT INTO t_func (nome_func, departamento, cidade) VALUES ('Eduardo', 'TI', 'Belo Horizonte');
COMMIT;
3 – Executar consulta com UNION e analisar com DBMS_XPLAN
SQL>
ALTER SESSION SET STATISTICS_LEVEL = ALL;
SELECT nome_func, cidade FROM t_func WHERE departamento = 'TI'
UNION
SELECT nome_func, cidade FROM t_func WHERE cidade = 'São Paulo';
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
.
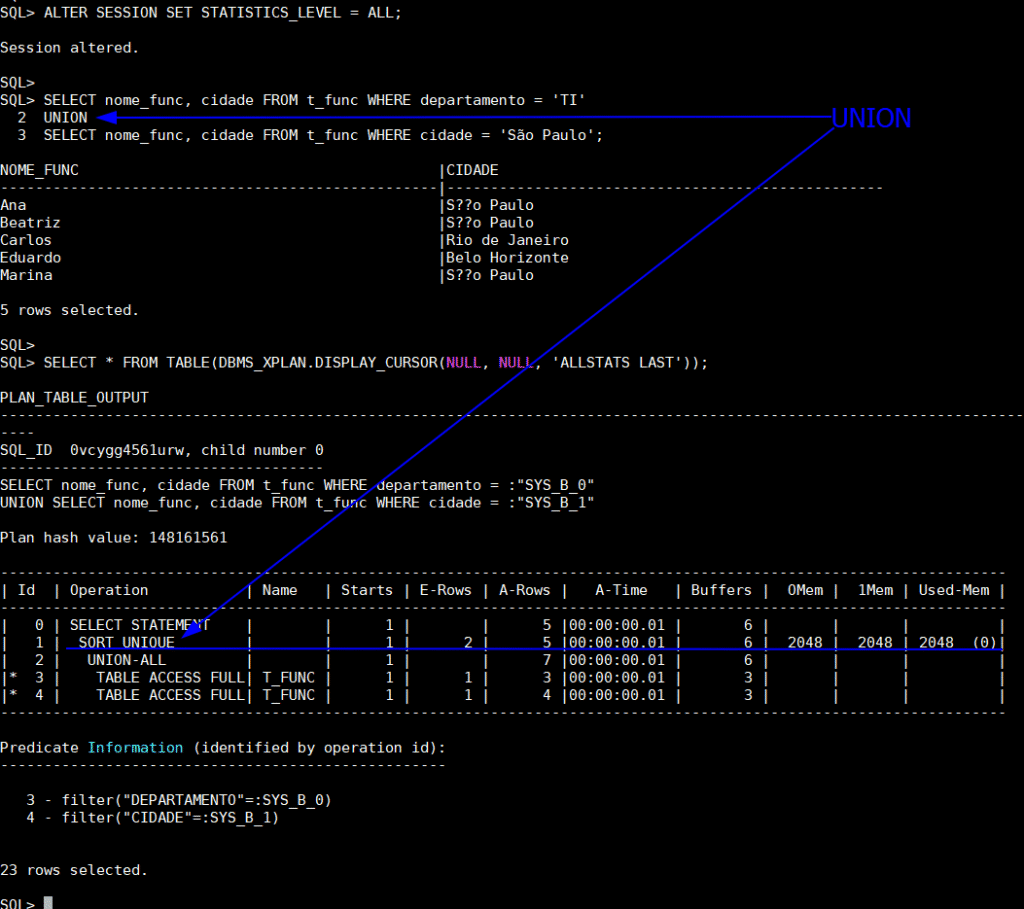
Interpretação UNION
- A operação
SORT UNIQUEfoi aplicada sobre os 7 registros combinados. - Após a deduplicação, apenas 5 linhas foram retornadas (
A-Rows = 5). - Neste cenário de teste simples, o custo foi baixo (6 buffers) e o uso de memória também foi modesto (
Used-Mem: 2048). - No entanto, é importante reforçar: esse impacto reduzido só é válido por se tratar de um conjunto pequeno.
- Se aplicarmos essa mesma operação em tabelas com milhões de linhas ou consultas executadas com alta frequência, o
SORTintroduzido peloUNIONpassa a consumir recursos computacionais, degradar o tempo de resposta e sobrecarregar CPU.
4 – Executar consulta com UNION ALL e analisar com DBMS_XPLAN
SQL>
ALTER SESSION SET STATISTICS_LEVEL = ALL;
SELECT nome_func, cidade FROM t_func WHERE departamento = 'TI'
UNION ALL
SELECT nome_func, cidade FROM t_func WHERE cidade = 'São Paulo';
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
.
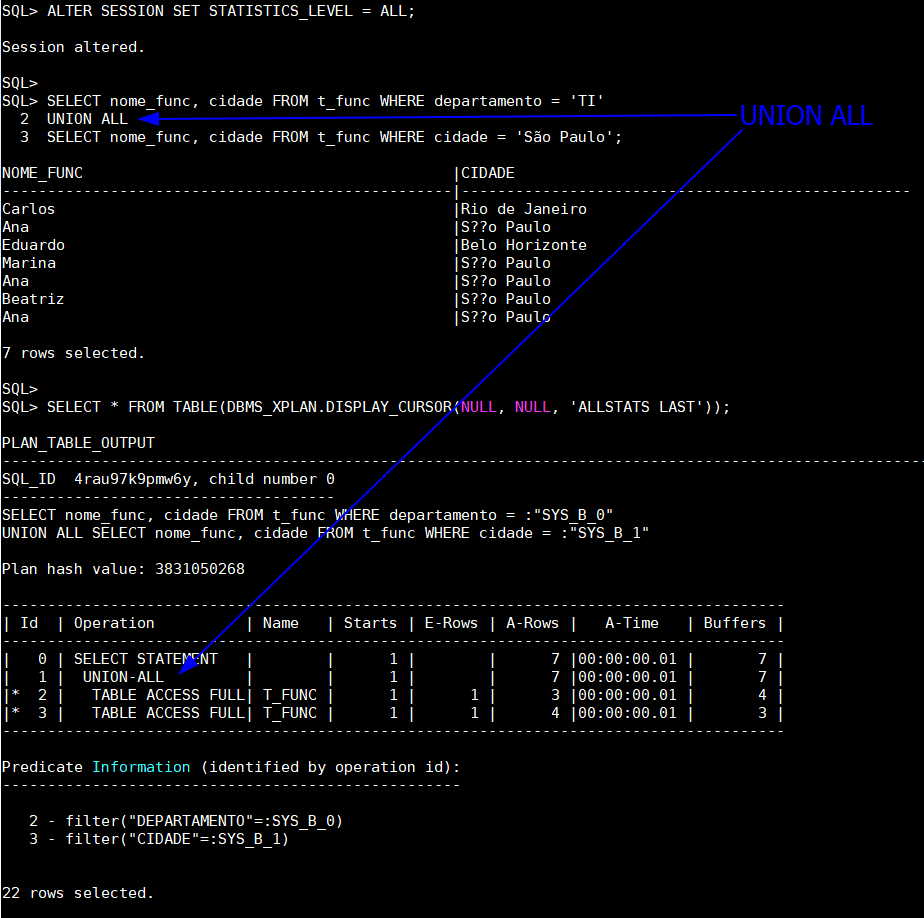
Interpretação UNION ALL
- A consulta com
UNION ALLapenas empilha os dois conjuntos de dados, sem remover duplicatas - Não há operação de ordenação, nem uso de memória extra ou
TEMP - O plano é mais enxuto, mais rápido e mais leve computacionalmente
- Ideal para cenários com grande volume, onde performance é prioritária e duplicatas são tratadas posteriormente
5 – Comparativo final
| Característica | UNION | UNION ALL |
|---|---|---|
| Elimina duplicados | Sim | Não |
Ordenação (SORT) | Sim (SORT UNIQUE) | Não |
| Custo de CPU | Maior | Menor |
| Uso de TEMP | Possível | Não |
| Performance | Mais lenta | Mais rápida |
| Quando usar | Duplicação for indesejada | duplicação aceitável ou impossível |
6 – Complemento: padrão comum (e indesejado) com UNION
É muito comum ver em consultas de sistemas legados ou scripts operacionais estruturas como esta:
SELECT 'A' tipo, destino, valor FROM tabela
UNION
SELECT 'B' tipo, destino, valor FROM tabela;
Nesse padrão, o valor da coluna tipo é literal e diferente em cada SELECT, o que garante que os registros nunca serão considerados duplicados pelo Oracle.
Mesmo assim, o banco aplica internamente:
- Um
UNION ALLpara empilhar os resultados - Um
SORT UNIQUEem seguida, para tentar identificar e eliminar duplicatas
O problema: esse SORT UNIQUE não encontra duplicações reais, mas ainda assim consome recursos como CPU, memória e, em casos maiores, até espaço em TEMP.
Por que isso acontece?
O Oracle não sabe que o valor 'A' e 'B' são fixos e distintos entre as partes. Ele simplesmente executa o operador UNION conforme definido, aplicando o processo padrão de deduplicação mesmo que seja desnecessário.
7 – Conclusão
Mesmo desenvolvedores experientes acabam usando esse padrão sem perceber o custo.
Por isso, vale revisar queries que utilizam UNION com literais fixas ou casos sem risco real de duplicação.
A regra aqui é simples: se não precisa eliminar duplicatas, use sempre UNION ALL.
e zas
#20250720 #DBASobrinho #GuinaNãoTinhaDó #BóBó #CaceteDeAgulha #OracleACE #MickeyLaVouEu #90Dias #SemChoro